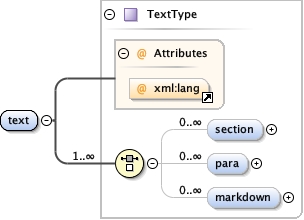
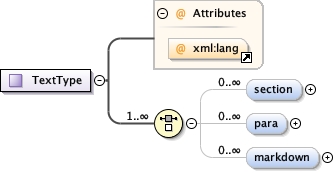
<xs:complexType name="TextType" mixed="true">
<xs:annotation>
<xs:documentation>tooltip: Text summary: A simple text desription. description: The "text" element allows for both formatted and unformatted text blocks to be included in EML. It can contain a number of relevant subsections that allow the use of titles, sections, and paragraphs in the text block. This markup is a subset of DocBook, or alternatively can be specified using Markdown text blocks.</xs:documentation>
</xs:annotation>
<xs:choice maxOccurs="unbounded">
<xs:element name="section" type="SectionType" minOccurs="0" maxOccurs="unbounded">
<xs:annotation>
<xs:documentation>tooltip: Section summary: A section of related text. description: The "section" element allows for grouping related paragraphs of text together, with an optional title. This markup is a subset of DocBook.</xs:documentation>
</xs:annotation>
</xs:element>
<xs:element name="para" type="ParagraphType" minOccurs="0" maxOccurs="unbounded">
<xs:annotation>
<xs:documentation>tooltip: Paragraph summary: A simple paragraph of text. description: The "paragraph" element allows for both formatted and unformatted text blocks to be included in EML. It can be plain text or text with a limited set of markup tags, including emphasis, subscript, superscript, and lists. This markup is a subset of DocBook.</xs:documentation>
</xs:annotation>
</xs:element>
<xs:element name="markdown" minOccurs="0" maxOccurs="unbounded">
<xs:annotation>
<xs:documentation>tooltip: Markdown summary: A block of text formatted with Markdown directives. description: Markdown is a family of text-based formatting directives that can be used to structure and format a block of text. A single markdown element in EML can contain multiple formatting directives that support creation of sections and subsections with headings, a wide variety of text formatting directives, the ability to include inline links to external content, and the ability to embed inline citations, figures, and tables. EML's markdown element follows the GitHub Flavored Markdown (GFM) extensions to the CommonMark specification. Clients that display EML should use a markdown preprocessor to convert the Markdown formatting into an appropriate display format such as HTML or PDF as appropriate. When a Markdown block is interleaved with other blocks of text such as section and paragraph elements from Docbook, the Markdown section should be interleaved as a block-level element in the flow of the document. This allows authors to specify, for example, an initial section in DocBook, followed by a Markdown section, and then possibly other sections in DocBook. This will likely be uncommon because Markdown and Docbook have similar formatting capabilities, but it may be helpful when converting legacy documents that use DocBook. Because markdown uses special characters that might be reserved by XML processors, one must be careful to escape such characters, which is typically done by embedding the text in a CDATA block, or other XML escaping measures. These escape sequences must be unescaped before parsing the text with a Markdown processor. Within a Markdown block, one can use embedded images to specify the location where an inline image should be displayed within the document. For example, the syntax for an embedded image uses the markdown reference syntax, for example ![Figure 1][fig.1.ab567w], where "fig.1.ab567w" is the unique id attribute for the entity containing the reference to the image. When client tools process such image links, they should inline the image data from that entity at the location specified, which may involve, for example, resolving the image url from an otherEntity section. This means that there is an implied link in all Markdown documents of the form [id]: url/to/image "Optional title attribute", which is derived from the metadata for each entity within a document. Users do not need to insert these links in order to use them, but client software that might be generating HTML from the markdown will likely need to generate them from the entity metadata if they are using an external Markdown pre-processor to handle conversion to HTML and other languages. Inline citations can also be used to cite scholarly works in the text of an EML document. This follows the Pandoc syntax for citation keys, in which the citation keys are in inside square brackets and separated by semicolons. Each citation is identified by a key, which consists of an ‘@’ symbol and the citation identifier from the entry for that citation. Citation keys may optionally have a prefix, a locator, and a suffix to further qualify what is being cited. For example, a simple citation would be constructed as '[@fegraus_2005]', and a list would be '[@jones_2001; @fegraus_2005]'. The keys must be present in either the 'id' field of a citation element in the EML document, or as the BibTex key in a 'bibtex' entry in the EML document. It is a validation error to cite an entry for which the corresponding citation key is not present in the EML document, and it is a validation error for the same citation key to be reused across citation and bibtex elements in the document (each citation identifier must be unique within the document). Clients that parse and display EML documents should first gather up all citation and bibtex elements in the document to create a citation database in bibtext format, and then pass that database along with the text in markdown sections to pandoc or an equivalent tool to convert the citations into properly formatted, human readable citations. Pandoc supports the use of Citation Style Language (CSL) files to specify the formatting of citations upon conversion. See http://citationstyles.org/ for more details. Because bulleted lists and other structures within Markdown are dependent on indenting the raw markdown text, authors and processors should pay close attention to formatting within the markdown block. In particular, if the XML document within which the markdown block is embedded is in an indented hierarchy, then the first non-whitespace character of the markdown block defines the column for the leftmost column of the markdown, and all subsequent markdown should be indented relative to that column. For example, if the first character of the markdown is in column 16 of the document, then all subsequent markdown lines in that block should also start on column 16. A bulleted list would start on column 16, and its sublist would be indented four space to column 20.</xs:documentation>
</xs:annotation>
<xs:complexType>
<xs:simpleContent>
<xs:extension base="res:NonEmptyStringType">
<!--
<xs:attribute name="syntax" type="i18nNonEmptyStringType" use="optional">
<xs:annotation>
<xs:appinfo>
<doc:tooltip>url</doc:tooltip>
<doc:summary>the Uniform Resource Locator for the cited work</doc:summary>
<doc:description>the url attribute contains the location of the work for a link. This markup is a subset of DocBook.</doc:description>
<doc:example>url="http://dublincore.org/documents/usageguide/"</doc:example>
</xs:appinfo>
</xs:annotation>
</xs:attribute>
-->
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:element>
</xs:choice>
<xs:attribute ref="xml:lang"/>
</xs:complexType> |